Introduction
This is an example that use Ponca to compute Screen Space Curvature in python using Cuda.
Installation and usage
This example requires the following python packages:
as well as a working cuda setup (tested with 5.0 and 7.0), and the lastest version of eigen dev branch which manage nvcc compiler.
To compile and run the example, call
cd build && make ssgls_py
cd examples/python && python ssgls.py -s 10 -p ./data/ssgls_sample_wc.png -n ./data/ssgls_sample_normal.png
The script will load the input pictures and compute the curvature for a screenspace neighborhood 10x10 pixels.

Screen-Space Curvature typical input. Left: world coordinates. Right: remapped normal vectors
It will generate this picture
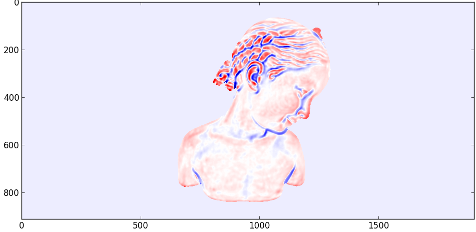
Screen-Space Curvature estimation
as well as the following trace on the standard output
Load CUDA kernel ........... DONE in 0.024 seconds.
Init Input data ............ DONE in 13.390 seconds.
Init queries ............... DONE in 0.720 seconds.
Set memory configuration ... DONE in 0.004 seconds.
Launch kernel .............. DONE in 1.505 seconds.
###########Configuration#############
Image size: 1902 x 911
NbQueries: 1732722
Scale: 10
################Results################
Max value: 25.3449363708
Min value: -31.8370857239
#######################################
- Note
- Don't worry about the important execution time, this example uses a naive and inefficient approach to represent queries with numpy, making the total process really slow. However, the real computation time in cuda is indicated by the last line of the timing trace. Note that we do not use any re-sampling technique, that is why this step is directly related to the scale parameter.
Cuda programming
Here are the technical details related to the cuda and python biding for screen-space curvature estimation.
Define fitting data structure
class MyPoint
{
public:
enum
{
Dim = 3
};
using Scalar = float;
using VectorType = Eigen::Matrix<Scalar, Dim, 1>;
using MatrixType = Eigen::Matrix<Scalar, Dim, Dim>;
using ScreenVectorType = Eigen::Matrix<Scalar, 2, 1>;
PONCA_MULTIARCH inline MyPoint(const VectorType& _pos = VectorType::Zero(),
const VectorType& _normal = VectorType::Zero(),
const ScreenVectorType& _spos = ScreenVectorType::Zero(), const Scalar _dz = 0.f)
: m_pos(_pos), m_normal(_normal), m_spos(_spos), m_dz(_dz)
{
}
PONCA_MULTIARCH inline const VectorType& pos() const { return m_pos; }
PONCA_MULTIARCH inline const VectorType& normal() const { return m_normal; }
PONCA_MULTIARCH inline const ScreenVectorType& spos() const { return m_spos; }
PONCA_MULTIARCH inline const float& dz() const { return m_dz; }
PONCA_MULTIARCH inline VectorType& pos() { return m_pos; }
PONCA_MULTIARCH inline VectorType& normal() { return m_normal; }
PONCA_MULTIARCH inline ScreenVectorType& spos() { return m_spos; }
PONCA_MULTIARCH inline float& dz() { return m_dz; }
private:
ScreenVectorType m_spos;
VectorType m_pos, m_normal;
float m_dz; // depth threshold
};
Define weighting functions
class ProjectWeightFunc : public Ponca::DistWeightFilter<MyPoint, Ponca::SmoothWeightKernel<Scalar>>
{
public:
using Scalar = MyPoint::Scalar;
using VectorType = MyPoint::VectorType;
using Base = Ponca::DistWeightFilter<MyPoint, Ponca::SmoothWeightKernel<Scalar>>;
/*
Default constructor (needed by Ponca). Note that the screenspace
evaluation position is specified as parameter
*/
PONCA_MULTIARCH inline ProjectWeightFunc(const VectorType& _refPos = VectorType::Zero(),
const ScreenVectorType& _refScreenPos = ScreenVectorType::Zero(),
const Scalar& _t = Scalar(1.f), const Scalar& _dz = Scalar(0.f))
: Base(_refPos, _t), m_refScreenPos(_refScreenPos), m_dz(_dz)
{
}
PONCA_MULTIARCH inline Scalar w(const VectorType& _q, const MyPoint& _attributes) const
{
Scalar d = (_attributes.spos() - m_refScreenPos).norm();
const Scalar dz = _attributes.dz();
if (d > m_t || dz > m_dz)
return Scalar(0.);
return m_wk.f(d / m_t);
}
private:
ScreenVectorType m_refScreenPos;
float m_dz;
};
Define fitting primitive
using Gls = Ponca::Basket<MyPoint, ProjectWeightFunc, Ponca::OrientedSphereFit, Ponca::GLSParam>;
Kernel
extern "C"
{
__global__ void doGLS_kernel(const int* _params, //[w, h, scale]
const float* _positions, const float* _normals, float* const _result)
{
const int x = int((blockIdx.x * blockDim.x) + threadIdx.x);
const int y = int((blockIdx.y * blockDim.y) + threadIdx.y);
const int& width = _params[0];
const int& height = _params[1];
if (x < width && y < height)
{
const int& scale = _params[2];
ScreenVectorType refScreenPos;
refScreenPos << Scalar(x), Scalar(y);
int dx, dy; // neighbor offset ids
int nx, ny; // neighbor ids
Gls gls;
gls.init();
gls.setNeighborFilter({getVector(x, y, width, height, _positions), refScreenPos, Scalar(scale)});
if (getVector(x, y, width, height, _normals).squaredNorm() == 0.f)
{
_result[getId(x, y, width, height, 0, 1)] = -1.0;
}
else
{
//_result[getId(x,y,width,height,0,1)] = getVector(x,y,width,height,_normals)(0);
VectorType n;
// collect neighborhood
const VectorType one = VectorType::Ones();
for (dy = -scale; dy != scale; dy++)
{
for (dx = -scale; dx != scale; dx++)
{
nx = x + dx;
ny = y + dy;
// Check image boundaries
if (nx >= 0 && ny >= 0 && nx < width && ny < height)
{
n = getVector(nx, ny, width, height, _normals);
// add nei only when the _normal is properly defined
// need to use an explicit floating point comparison with pycuda
if (n.squaredNorm() != 0.f)
{
// RGB to XYZ remapping
n = Scalar(2.f) * n - one;
n.normalize();
// GLS computation
gls.addNeighbor(
MyPoint(getVector(nx, ny, width, height, _positions), n, ScreenVectorType(nx, ny)));
}
}
}
}
// closed form minimization
gls.finalize();
_result[getId(x, y, width, height, 0, 1)] = gls.kappa();
}
}
}
}
Memory access
We use numpy to format the input data, filled by dimension (in object space) and then by the screen-space coordinates:
__device__ int getId(const int _x, const int _y, const int _width, const int _height, const int _component,
const int _nbComponent)
{
return (_component) + _nbComponent * (_x + _y * _width);
}
__device__ VectorType getVector(const int _x, const int _y, const int _width, const int _height, const float* _buffer)
{
VectorType r;
r << Scalar(_buffer[getId(_x, _y, _width, _height, 0, 3)]), Scalar(_buffer[getId(_x, _y, _width, _height, 1, 3)]),
Scalar(_buffer[getId(_x, _y, _width, _height, 2, 3)]);
return r;
}
Python script
We use numpy to format input data.
import pycuda.autoinit
import pycuda.driver as drv
import numpy as np
from PIL import Image
import time
import sys, getopt
import matplotlib.pyplot as plt
start_time = 0.0
def startTimer(funcname, quiet):
global start_time
if not quiet:
sys.stdout.write(funcname)
sys.stdout.flush()
start_time = time.time()
def stopTimer(quiet):
elapsed_time = time.time() - start_time
if not quiet:
print(f"DONE in {elapsed_time:.3f} seconds.")
def loadKernel():
module = drv.module_from_file("ssgls.ptx")
glsKernel = module.get_function("doGLS_kernel")
return module, glsKernel
def initInputData(imgNormPath, imgwcPath):
i_normals = Image.open (imgNormPath)
i_positions = Image.open (imgwcPath)
(w,h) = i_positions.size
l = w * h
normals = np.array(i_normals).reshape(l, 3).astype(np.float32) / 255.0
positions = np.array(i_positions).reshape(l, 3).astype(np.float32) / 255.0
positions = positions * 2.0 - 1.0
normals = normals.reshape(-1)
positions = positions.reshape(-1)
return w, h, normals, positions
def initQueries(w, h):
nbQueries = w * h
queries = np.zeros(2 * nbQueries, dtype=np.float32)
for j in range(h):
for i in range(w):
idx = 2 * (i + j * w)
queries[idx] = i
queries[idx + 1] = j
return nbQueries, queries
def main(argv):
scale = 10
imgNormPath = ''
imgwcPath = ''
quiet = False
outputPath = ''
try:
opts, args = getopt.getopt(
argv,
"s:p:n:o:q",
["scale=", "positions=", "normals=", "output=", "quiet"]
)
except getopt.GetoptError:
print("ssgls.py -s <scale> -p <image path> -n <normals>")
sys.exit(2)
for opt, arg in opts:
if opt == '-h':
print("ssgls.py -s <scale> -p <image path> -n <normals>")
sys.exit()
elif opt in ("-s", "--scale"):
scale = int(arg)
elif opt in ("-p", "--imgpath"):
imgwcPath = arg
elif opt in ("-n", "--normals"):
imgNormPath = arg
elif opt in ("-o", "--output"):
outputPath = arg
elif opt in ("-q", "--quiet"):
quiet = True
startTimer("Load CUDA kernel ........... ", quiet)
module, glsKernel = loadKernel()
stopTimer(quiet)
startTimer("Init Input data ............ ", quiet)
w, h, normals, positions = initInputData(imgNormPath, imgwcPath)
stopTimer(quiet)
nbQueries = w * h
startTimer("Init result array memory ... ", quiet)
result = np.zeros(nbQueries, dtype=np.float32)
stopTimer(quiet)
blockSize = 32
gridWidth = w // blockSize
gridHeight = h // blockSize
w = np.int32(w)
h = np.int32(h)
scale = np.int32(scale)
startTimer("Launch kernel .............. ", quiet)
glsKernel(
drv.In(np.array([w, h, scale])),
drv.In(positions),
drv.In(normals),
drv.Out(result),
block=(blockSize, blockSize, 1),
grid=(gridWidth, gridHeight)
)
stopTimer(quiet)
result[np.isnan(result)] = 0
if not quiet:
print("\n###########Configuration#############")
print(f"Image size: {w} x {h}")
print(f"NbQueries: {nbQueries}")
print(f"Scale: {scale}")
print("################Results################")
print(f"Max value: {result.max()}")
print(f"Min value: {result.min()}")
print("#######################################")
scaleFactor = max(abs(result.max()), abs(result.min()))
if outputPath == '':
plt.imshow( result.reshape(h, w),
vmin = -scaleFactor,
vmax = scaleFactor,
cmap = 'seismic'
)
plt.show()
else:
plt.imsave(
fname = outputPath,
arr = result.reshape(h, w),
vmin = -1.0,
vmax = 1.0,
cmap = 'seismic'
)
if __name__ == "__main__":
main(sys.argv[1:])